1. はじめに
こんにちは!株式会社Definerのライターチームです!
今回は、BigQueryでビッグデータを自由に使用する方法について気になりますよね。
実際の画面や、資源を見ながら詳しく解説していきましょう。
2. 目的・ユースケース
この記事では、BigQueryでビッグデータを自由に使用したいときに、参考になる情報やプラクティスをまとめています。
3. BigQueryとは
まずは、BigQueryについておさらいします。
BigQueryは、Google Cloudが提供するサーバレスなビッグデータ解析サービスです。
スケーラブルでコストパフォーマンスに優れており、テラバイトやペタバイト単位のデータ分析が可能です。
BigQueryの特徴
・データ処理速度
ペタバイト、数億行といったビッグデータに対して、従来であれば多くの時間を要していた集計・分析を高速に実行できる
・安価なコスト
BigQueryはSQLで抽出したデータ量とテーブルに保存されているデータに対して従量課金されますが、他ベンダーのサービスと比較し非常に安価です。
・操作性
簡単なSQLの知識があれば、クエリを作成・実行することができます。
4. BigQueryを試してみる
早速、BigQueryを試してみます。
①データセット準備
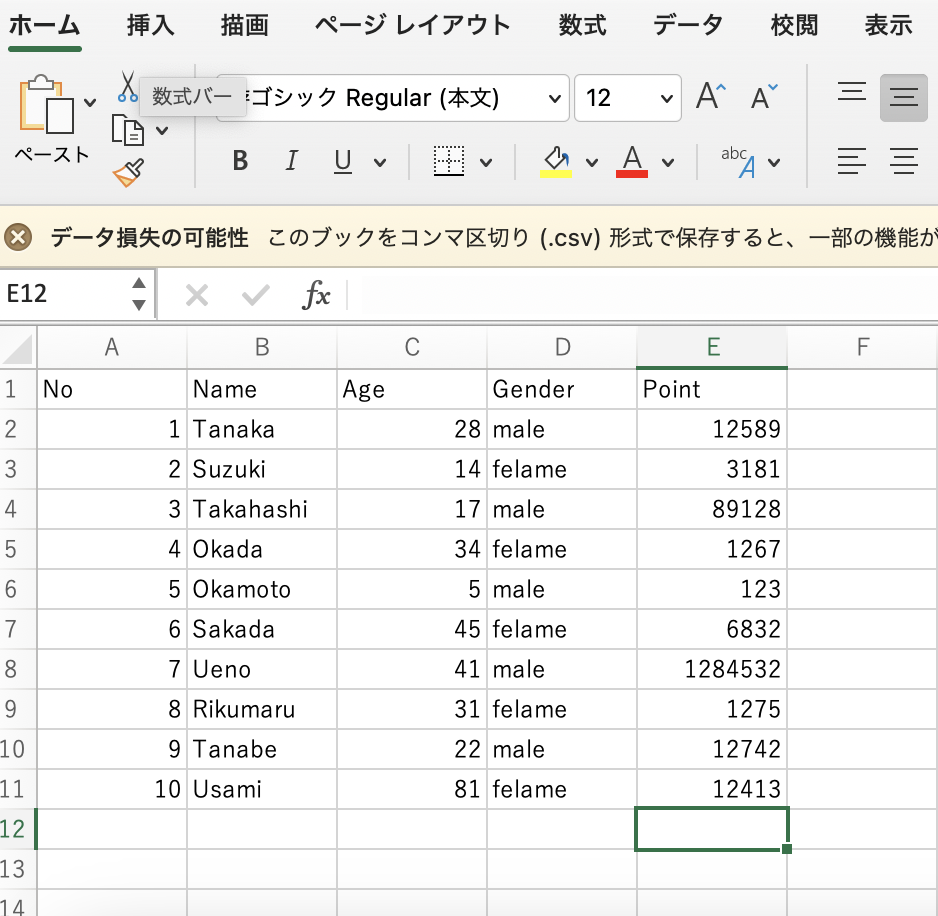
まずは、CSVファイルを準備します。
サンプルとして、以下のようなファイルを準備しました!
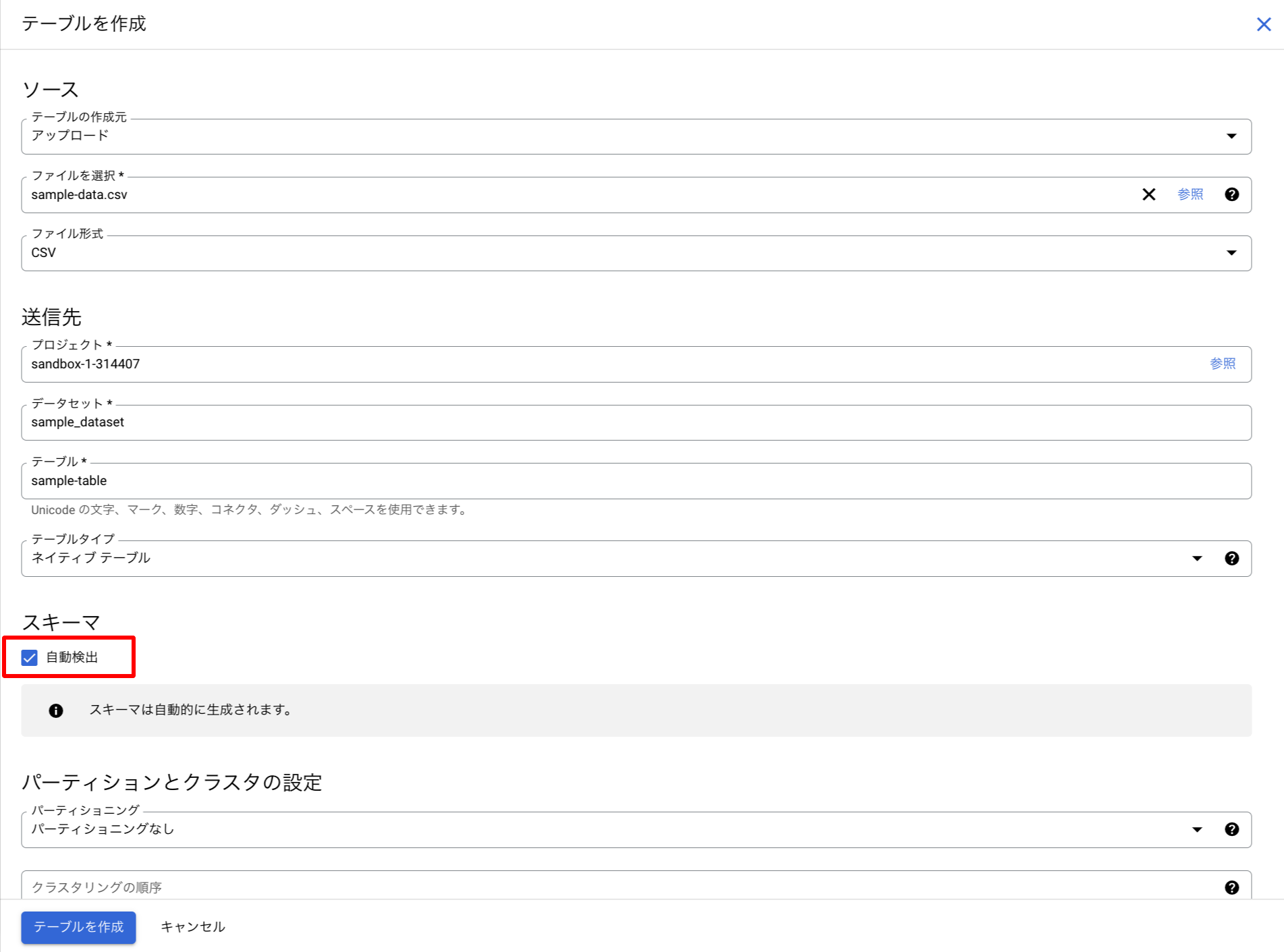
 ②BigQueryテーブルの作成
BigQueryコンソールにアクセスし、「テーブルの作成」
先ほどのCSVファイルをアップロードし、テーブルを作成します。
ポイントとして、スキーマの自動検出をオンにしてください。
②BigQueryテーブルの作成
BigQueryコンソールにアクセスし、「テーブルの作成」
先ほどのCSVファイルをアップロードし、テーブルを作成します。
ポイントとして、スキーマの自動検出をオンにしてください。
 ③クエリ実行
以下クエリを実行すると、結果が表示されました!
③クエリ実行
以下クエリを実行すると、結果が表示されました!
②BigQueryテーブルの作成
BigQueryコンソールにアクセスし、「テーブルの作成」
先ほどのCSVファイルをアップロードし、テーブルを作成します。
ポイントとして、スキーマの自動検出をオンにしてください。
③クエリ実行
以下クエリを実行すると、結果が表示されました!
SELECT Name, age , Point from ${テーブル名} ORDER BY Point DESC LIMIT 5: 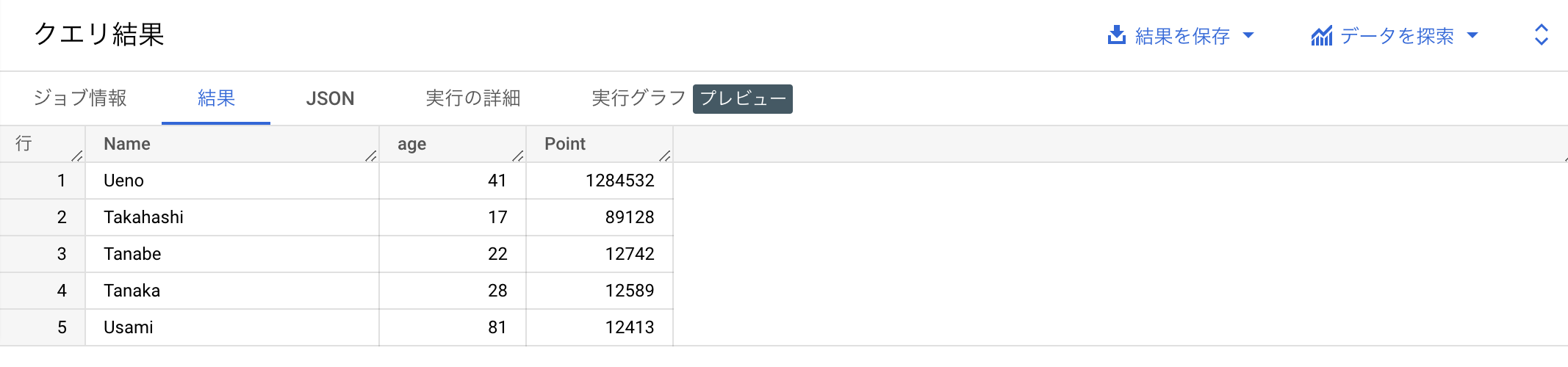
5. 引用・参考記事
6. 独自ソリューション「PrismScaler」について
PrismScalerは、開発・運用を要さずにたった3ステップで、AWSやAzure、GCPなどのマルチクラウド基盤構築を実現するWebサービスです。
エンジニアの大変な作業を肩代わり
・自動構築
・自動監視
・構成可視化
クラウド基盤に関わる作業を以上のように効率化します。
SRE/DevOpsエンジニアが行う大変な作業を肩代わりします。
高品質な汎用クラウド基盤の実現
・クラウド基盤構築/クラウド移行
・クラウドの保守運用・コスト最適化
など幅広い利用シーンを想定しています。IaaSやPaaSを適切に組み合わせた数百を超える高品質な汎用クラウド基盤を容易に実現できます。
興味を持たれた方には、無料で資料を提供しております。
お気軽にご相談ください。

7. お問合せ
株式会社Definerでは、
・ITの上流から下流まで一気通貫のワンストップソリューションをご提供。
・AIやクラウドのITインフラなど、先進的なIT技術のコンサルティングから要件定義 / 設計開発 / 実装、保守運用に至るまでの統合的な支援にコミット。
・少ないエンジニアで事業が成長する仕組みづくりの実現。
・エンジニアが喜ぶ、採用しやすい環境づくりの実現。
・高速なアジャイル開発環境の実現。
・自社プロダクトとしてPrismScalerを展開。
上記事業内容を進行しております。
※「開発者ブログ」では、エンジニアの入門編として有益な情報を無料公開しています。
ご相談やお問い合わせは「株式会社Definer」へ。
8. Definerに関して。
・ Definer Incは、ITの上流から下流まで一気通貫のワンストップソリューションをご提供しております。
・ AIやクラウドのITインフラなど、先進的なIT技術のコンサルティングから要件定義 / 設計開発 / 実装、保守運用に至るまでの統合的な支援にコミットしています。
・ DevOpsとCI/CDコンサルティングにより「少ないエンジニアで事業が成長する仕組みづくり」「エンジニアが喜ぶ、採用しやすい環境づくり」「高速なアジャイル開発環境」を実現しています。
・ また、自社プロダクトとしてPrismScalerを展開しております。PrismScalerは、AWS、Azure、GCPなどのマルチクラウド / ITインフラの高品質かつ迅速な、「自動構築」「自動監視」「問題検知」「構成可視化」を実現します。